Postgres Storage
存储
内存
共享内存
本地内存
缓存
内存上下文
缓存空间管理
数据块的缓存,减少磁盘IO,有共享缓存和进程缓存Cache
数据块之外的缓存,例如系统表- 系统表缓存不会缓存整个表,是以block为单位缓存?
虚拟文件描述符
系统中文件有打开的上限,使用VFD可以突破这种限制,本质上是一个LRU缓存空闲空间定位
快速定位磁盘中的空闲空间以插入数据进程间通信 使用共享内存或者信号量通信
读取过程
- 从系统表中读取表的元数据信息构造元组信息
- 尝试从缓存读取数据
- 使用SMGR从磁盘读取数据到缓存中,SMGR是一个抽象层,用于实现不同存储介质的管理
- SMGR和存储介质之间使用VFD来管理文件描述符,以突破系统的FD限制
- 标记删除,vacuum清理数据
- FSM记录空闲空间
磁盘
表文件
SMGR
VFD
FSM
select * from pg_relation_filepath(‘idx’);
Page 结构
工具汇总说明
create extension pageinspect;
get_raw_page(relname text, fork text, blkno int)
返回执行表的page,text指定类型,默认是main,代表普通page,使用fsm或者vm查看其他类型,可以省略
page_header(page bytea)
查看page头,输入是page数组,使用上面的函数的输出作为参数
fsm_page_contents(page bytea) returns text
查看fsm页面结构
SELECT fsm_page_contents(get_raw_page('t1', 'fsm', 0));
=== HEAP相关
heap_page_items(page bytea)
查看page的具体信息
heap_tuple_infomask_flags(t_infomask integer, t_infomask2 integer) returns record
查看mask的具体含义,具体的使用方法为
SELECT * FROM heap_page_items(get_raw_page('a', 0)), LATERAL heap_tuple_infomask_flags(t_infomask, t_infomask2) WHERE t_infomask IS NOT NULL OR t_infomask2 IS NOT NULL order by lp desc;
输出为
t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data | raw_flags | combined_flags
-------------+------------+--------+----------+-------+------------+--------------------------------------------------------------------------+----------------
3 | 2305 | 24 | 10000000 | | \x02000000 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_INVALID} | {}
8195 | 1281 | 24 | 10000000 | | \x01000000 | {HEAP_HASNULL,HEAP_XMIN_COMMITTED,HEAP_XMAX_COMMITTED,HEAP_KEYS_UPDATED} | {}
主要目的是查看数据的mask的信息
=== Btree相关
bt_metap(relname text)
查看btree元数据信息
bt_page_stats(relname text, blkno int)
查看btree page的统计信息
bt_page_items(relname text, blkno int) 或者 bt_page_items(page bytea) returns setof record
查看具体的信息,可以指定index或者直接使用page byte
typedef struct PageHeaderData
{
/* XXX LSN is member of *any* block, not only page-organized ones */
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog record for last change to this page */
uint16 pd_checksum; /* checksum */
uint16 pd_flags; /* flag bits, see below */
LocationIndex pd_lower; /* offset to start of free space */
LocationIndex pd_upper; /* offset to end of free space */
LocationIndex pd_special; /* offset to start of special space */
uint16 pd_pagesize_version;
TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array */
} PageHeaderData;
void
PageInit(Page page, Size pageSize, Size specialSize)
{
PageHeader p = (PageHeader) page;
specialSize = MAXALIGN(specialSize);
Assert(pageSize == BLCKSZ);
Assert(pageSize > specialSize + SizeOfPageHeaderData);
/* Make sure all fields of page are zero, as well as unused space */
MemSet(p, 0, pageSize);
p->pd_flags = 0;
p->pd_lower = SizeOfPageHeaderData;
p->pd_upper = pageSize - specialSize;
p->pd_special = pageSize - specialSize;
PageSetPageSizeAndVersion(page, pageSize, PG_PAGE_LAYOUT_VERSION);
/* p->pd_prune_xid = InvalidTransactionId; done by above MemSet */
}
大小为 pageSize,默认为8k,最开始是PageHeader,
- 数据的变动以page为单位,不直接和存储交互,先把数据块读到缓存,然后在进行insert或者update或者delete,具体的函数有
- heap_update
- heap_multi_insert
- heap_insert
tuple结构如下
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a * speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
// hot相关信息,
// hot指的是数据在更新的时候,如果有index,会同事更新index,即使没有修改到index属性的数据,此时index中也会有一条数据的链表,为了节约空间,在满足
// 1. 没有修改到index属性数据
// 2. 数组修改限于在同一个page内,此时index不会有额外的数据,查找的时候从index找到最老的数据,按照数据链查找到最新数据即可
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
page具体的操作代码在storage/page目录下,建议进行 15445 的实验,可以更好的理解page相关的操作,这里page的操作总体类似,主要是具体的数据结构和某些特定的方法需要时间进行记忆,但是大的方向上似曾相识。
RelationPutHeapTuple insert tuple到page中,根据head中的信息,计算insert的位置,其中page中的数据从首位向中心靠齐,尾部为数据,前面为offset,使用pd_lower和pd_upper进行管理,最后为柔性数组,数据在最后,
在内存总操作的时候,使用偏移可以直接定位到数据,具体使用pageinspect插件查看
调试heap_page_items函数,结合官网和源码熟悉数据的组织结构
esoye=# table a ;
a | b
---+---
1 | 1
5 | 2
2 | 2
7 | 7
1 | 9
(5 rows)
esoye=# select * from page_header(get_raw_page('a', 0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
-----------+----------+-------+-------+-------+---------+----------+---------+-----------
0/5BD92B8 | 0 | 0 | 64 | 7872 | 8192 | 8192 | 4 | 788
(1 row)
select * from heap_page_items(get_raw_page('a', 0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------
1 | 8160 | 1 | 32 | 787 | 0 | 0 | (0,1) | 2 | 2304 | 24 | | | \x0100000001000000
2 | 8128 | 1 | 32 | 788 | 788 | 0 | (0,3) | 2 | 1312 | 24 | | | \x0200000002000000
3 | 8096 | 1 | 32 | 788 | 788 | 1 | (0,4) | 2 | 9504 | 24 | | | \x0300000002000000
4 | 8064 | 1 | 32 | 788 | 788 | 2 | (0,5) | 2 | 9504 | 24 | | | \x0400000002000000
5 | 8032 | 1 | 32 | 788 | 0 | 3 | (0,5) | 2 | 10496 | 24 | | | \x0500000002000000
6 | 8000 | 1 | 32 | 791 | 0 | 0 | (0,6) | 2 | 2304 | 24 | | | \x0200000002000000
7 | 7968 | 1 | 32 | 792 | 792 | 0 | (0,8) | 2 | 544 | 24 | | | \x0400000004000000
8 | 7936 | 1 | 32 | 792 | 0 | 1 | (0,8) | 2 | 10752 | 24 | | | \x0600000004000000
9 | 7904 | 1 | 32 | 793 | 0 | 0 | (0,9) | 2 | 2304 | 24 | | | \x0700000007000000
10 | 7872 | 1 | 32 | 794 | 0 | 0 | (0,10) | 2 | 2048 | 24 | | | \x0100000009000000
(10 rows)
pageinspect插件get_raw_page直接获得指定page的数据,然后在heap_page_items函数中解读page
page结构
tuple结构
首先是PageHeader,大小为24,在函数page_header中直接获取到page之后,进行强转,然后读取header中的数据即可,其中lsn和wal有关,后面需要调研机制,prune_xid和数据剪枝有关,后面调研。再然后在page得最后由部分数据和index有关,这里不关注
然后是具体的数据组织,在header之后,开始数据的存储,数据使用index定位偏移,实际的数据从尾部进行增长。定位数据偏移的数据结构为ItemId,
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
lp_off是实际的数据的偏移的位置,lp_flags表示数据状态,例如死元组,或者重定位的数据,一般是1,表示LP_NORMAL,lp_len是数据的长度,具体案例见上面的例子
Datum heap_page_items(PG_FUNCTION_ARGS) {
bytea *raw_page = PG_GETARG_BYTEA_P(0);
heap_page_items_state *inter_call_data = NULL;
FuncCallContext *fctx;
int raw_page_size;
if (!superuser())
ereport(ERROR, (errcode(ERRCODE_INSUFFICIENT_PRIVILEGE), errmsg("must be superuser to use raw page functions")));
raw_page_size = VARSIZE(raw_page) - VARHDRSZ;
if (SRF_IS_FIRSTCALL()) {
TupleDesc tupdesc;
MemoryContext mctx;
if (raw_page_size < SizeOfPageHeaderData)
ereport(ERROR,
(errcode(ERRCODE_INVALID_PARAMETER_VALUE), errmsg("input page too small (%d bytes)", raw_page_size)));
fctx = SRF_FIRSTCALL_INIT();
mctx = MemoryContextSwitchTo(fctx->multi_call_memory_ctx);
inter_call_data = palloc(sizeof(heap_page_items_state));
/* Build a tuple descriptor for our result type */
if (get_call_result_type(fcinfo, NULL, &tupdesc) != TYPEFUNC_COMPOSITE)
elog(ERROR, "return type must be a row type");
inter_call_data->tupd = tupdesc;
inter_call_data->offset = FirstOffsetNumber;
inter_call_data->page = VARDATA(raw_page);
fctx->max_calls = PageGetMaxOffsetNumber(inter_call_data->page);
fctx->user_fctx = inter_call_data;
MemoryContextSwitchTo(mctx);
}
fctx = SRF_PERCALL_SETUP();
inter_call_data = fctx->user_fctx;
if (fctx->call_cntr < fctx->max_calls) {
Page page = inter_call_data->page;
HeapTuple resultTuple;
Datum result;
ItemId id;
Datum values[14];
bool nulls[14];
uint16 lp_offset;
uint16 lp_flags;
uint16 lp_len;
memset(nulls, 0, sizeof(nulls));
/* Extract information from the line pointer */
id = PageGetItemId(page, inter_call_data->offset);
lp_offset = ItemIdGetOffset(id);
lp_flags = ItemIdGetFlags(id);
lp_len = ItemIdGetLength(id);
values[0] = UInt16GetDatum(inter_call_data->offset);
values[1] = UInt16GetDatum(lp_offset);
values[2] = UInt16GetDatum(lp_flags);
values[3] = UInt16GetDatum(lp_len);
/*
* We do just enough validity checking to make sure we don't reference
* data outside the page passed to us. The page could be corrupt in
* many other ways, but at least we won't crash.
*/
if (ItemIdHasStorage(id) && lp_len >= MinHeapTupleSize && lp_offset == MAXALIGN(lp_offset) &&
lp_offset + lp_len <= raw_page_size) {
HeapTupleHeader tuphdr;
bytea *tuple_data_bytea;
int tuple_data_len;
/* Extract information from the tuple header */
// 由id定位到具体的tuple,然后进行读取,这里需要对照tuple的数据结构
tuphdr = (HeapTupleHeader)PageGetItem(page, id);
values[4] = UInt32GetDatum(HeapTupleHeaderGetRawXmin(tuphdr));
values[5] = UInt32GetDatum(HeapTupleHeaderGetRawXmax(tuphdr));
/* shared with xvac */
values[6] = UInt32GetDatum(HeapTupleHeaderGetRawCommandId(tuphdr));
// 数据的具体位置,使用此字段可以直接定位一个tuple的位置
values[7] = PointerGetDatum(&tuphdr->t_ctid);
values[8] = UInt32GetDatum(tuphdr->t_infomask2);
values[9] = UInt32GetDatum(tuphdr->t_infomask);
values[10] = UInt8GetDatum(tuphdr->t_hoff);
/* Copy raw tuple data into bytea attribute */
tuple_data_len = lp_len - tuphdr->t_hoff;
tuple_data_bytea = (bytea *)palloc(tuple_data_len + VARHDRSZ);
SET_VARSIZE(tuple_data_bytea, tuple_data_len + VARHDRSZ);
memcpy(VARDATA(tuple_data_bytea), (char *)tuphdr + tuphdr->t_hoff, tuple_data_len);
values[13] = PointerGetDatum(tuple_data_bytea);
/*
* We already checked that the item is completely within the raw
* page passed to us, with the length given in the line pointer.
* Let's check that t_hoff doesn't point over lp_len, before using
* it to access t_bits and oid.
*/
if (tuphdr->t_hoff >= SizeofHeapTupleHeader && tuphdr->t_hoff <= lp_len &&
tuphdr->t_hoff == MAXALIGN(tuphdr->t_hoff)) {
if (tuphdr->t_infomask & HEAP_HASNULL) {
int bits_len;
bits_len = BITMAPLEN(HeapTupleHeaderGetNatts(tuphdr)) * BITS_PER_BYTE;
values[11] = CStringGetTextDatum(bits_to_text(tuphdr->t_bits, bits_len));
} else
nulls[11] = true;
if (tuphdr->t_infomask & HEAP_HASOID_OLD)
values[12] = HeapTupleHeaderGetOidOld(tuphdr);
else
nulls[12] = true;
} else {
nulls[11] = true;
nulls[12] = true;
}
} else {
/*
* The line pointer is not used, or it's invalid. Set the rest of
* the fields to NULL
*/
int i;
for (i = 4; i <= 13; i++) nulls[i] = true;
}
/* Build and return the result tuple. */
resultTuple = heap_form_tuple(inter_call_data->tupd, values, nulls);
result = HeapTupleGetDatum(resultTuple);
inter_call_data->offset++;
SRF_RETURN_NEXT(fctx, result);
} else
SRF_RETURN_DONE(fctx);
}
index
btree
select * from bt_metap('idx');
select * from bt_page_stats('idx',3);
SELECT * FROM bt_page_items('idx', 3);
- Implement an algorithm for building the index and map the data into pages (for the buffer cache manager to uniformly process each index).
- Search information in the index by a predicate in the form “indexed-field operator expression”.
- Evaluate the index usage cost.
- Manipulate the locks required for correct parallel processing.
- Generate write-ahead log (WAL) records.
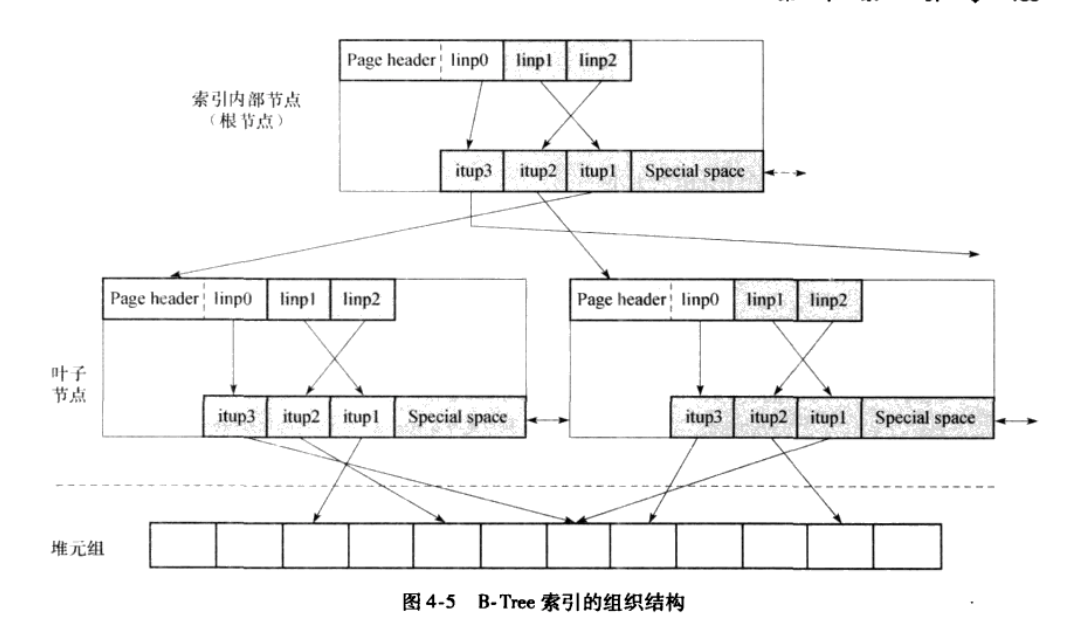
- 树节点默认8k,按照page的方式进行组织,几乎和heap的组织格式类似,尾部有一个特殊区域,常规page中也有,但是并未启用
typedef struct BTPageOpaqueData
{
BlockNumber btpo_prev; /* left sibling, or P_NONE if leftmost */
BlockNumber btpo_next; /* right sibling, or P_NONE if rightmost */
uint32 btpo_level; /* tree level --- zero for leaf pages */
uint16 btpo_flags; /* flag bits, see below */
BTCycleId btpo_cycleid; /* vacuum cycle ID of latest split */
} BTPageOpaqueData;
#define BTP_LEAF (1 << 0) /* leaf page, i.e. not internal page */
#define BTP_ROOT (1 << 1) /* root page (has no parent) */
#define BTP_DELETED (1 << 2) /* page has been deleted from tree */
#define BTP_META (1 << 3) /* meta-page */
#define BTP_HALF_DEAD (1 << 4) /* empty, but still in tree */
#define BTP_SPLIT_END (1 << 5) /* rightmost page of split group */
#define BTP_HAS_GARBAGE (1 << 6) /* page has LP_DEAD tuples (deprecated) */
#define BTP_INCOMPLETE_SPLIT (1 << 7) /* right sibling's downlink is missing */
#define BTP_HAS_FULLXID (1 << 8) /* contains BTDeletedPageData */
主要保存当前page的prev和next,以及level和flag,flag状态如上,此项可以使用bt_page_stats进行观察
实现来自于一篇古老的论文,添加额外的特性使得他获得更高的并发度。和常规Btree区别是
每层兄弟节点之间使用指针相连
每层非最右节点保存当前节点的最大值
1. 在查找得时候,如果已经查找到子节点,此时表示数据一定在当前的page中,但是假如在查找的过程中page分裂了,则此时可以快速使用high key 进行判断,此时在无需对整个树加锁假设一个indextuple大小为16,则完整表示一个item的空间大小为(16 + 4),再加上header和special计算得一个8k的page大约可以保存407条记录,可以简单的测试一下,最终page的free space 的大小为8
create table a (a int, b int);
create index idx on a(b);
insert into a select g, random() * 100000, g%999 from generate_series(1, 400) g;
esoye=# select * from bt_metap('idx');
magic | version | root | level | fastroot | fastlevel | last_cleanup_num_delpages | last_cleanup_num_tuples | allequalimage
--------+---------+------+-------+----------+-----------+---------------------------+-------------------------+---------------
340322 | 4 | 3 | 1 | 1 | 0 | 0 | -1 | t
(1 row)
esoye=# SELECT * FROM bt_page_items('idx', 3);
itemoffset | ctid | itemlen | nulls | vars | data | dead | htid | tids
------------+-------+---------+-------+------+------+------+------+------
1 | (1,0) | 8 | f | f | | | |
(1 row)
esoye=# select * from bt_page_stats('idx',1);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo_level | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------------+------------
1 | l | 400 | 0 | 16 | 8192 | 148 | 0 | 0 | 0 | 1
(1 row)
index function
pg中所有的数据类型,或者函数,索引等都可以使用元数据管理,感觉他在底层是搭了一个架子,其他东西都是架子上的工具
所有的index都有一个对应的handle,btree对应的是bthandler,内部把btree的关键的操作函数指针赋给IndexAmRoutine,
Datum
bthandler(PG_FUNCTION_ARGS)
{
IndexAmRoutine *amroutine = makeNode(IndexAmRoutine);
amroutine->amstrategies = BTMaxStrategyNumber;
amroutine->amsupport = BTNProcs;
amroutine->amoptsprocnum = BTOPTIONS_PROC;
amroutine->amcanorder = true;
amroutine->amcanorderbyop = false;
amroutine->amcanbackward = true;
amroutine->amcanunique = true;
amroutine->amcanmulticol = true;
amroutine->amoptionalkey = true;
amroutine->amsearcharray = true;
amroutine->amsearchnulls = true;
amroutine->amstorage = false;
amroutine->amclusterable = true;
amroutine->ampredlocks = true;
amroutine->amcanparallel = true;
amroutine->amcaninclude = true;
amroutine->amusemaintenanceworkmem = false;
amroutine->amparallelvacuumoptions =
VACUUM_OPTION_PARALLEL_BULKDEL | VACUUM_OPTION_PARALLEL_COND_CLEANUP;
amroutine->amkeytype = InvalidOid;
amroutine->ambuild = btbuild;
amroutine->ambuildempty = btbuildempty;
amroutine->aminsert = btinsert;
amroutine->ambulkdelete = btbulkdelete;
amroutine->amvacuumcleanup = btvacuumcleanup;
amroutine->amcanreturn = btcanreturn;
amroutine->amcostestimate = btcostestimate;
amroutine->amoptions = btoptions;
amroutine->amproperty = btproperty;
amroutine->ambuildphasename = btbuildphasename;
amroutine->amvalidate = btvalidate;
amroutine->amadjustmembers = btadjustmembers;
amroutine->ambeginscan = btbeginscan;
amroutine->amrescan = btrescan;
amroutine->amgettuple = btgettuple;
amroutine->amgetbitmap = btgetbitmap;
amroutine->amendscan = btendscan;
amroutine->ammarkpos = btmarkpos;
amroutine->amrestrpos = btrestrpos;
amroutine->amestimateparallelscan = btestimateparallelscan;
amroutine->aminitparallelscan = btinitparallelscan;
amroutine->amparallelrescan = btparallelrescan;
PG_RETURN_POINTER(amroutine);
}
其他index和表类似,都有自己的接口
create
建立index
a | b | c | ctid
--------+--------+------+-----------
19928 | 0 | 947 | (107,133)
883 | 1 | 883 | (4,143)
18064 | 1 | 82 | (97,119)
89238 | 2 | 327 | (482,68)
96552 | 3 | 648 | (521,167)
96831 | 3 | 927 | (523,76)
22937 | 6 | 959 | (123,182)
59675 | 6 | 734 | (322,105)
76742 | 10 | 818 | (414,152)
42563 | 11 | 605 | (230,13)
53421 | 11 | 474 | (288,141)
41441 | 12 | 482 | (224,1)
88531 | 12 | 619 | (478,101)
14010 | 17 | 24 | (75,135)
57127 | 17 | 184 | (308,147)
31710 | 19 | 741 | (171,75)
58259 | 19 | 317 | (314,169)
61877 | 19 | 938 | (334,87)
20741 | 22 | 761 | (112,21)
83730 | 22 | 813 | (452,110)
92344 | 22 | 436 | (499,29)
18195 | 24 | 213 | (98,65)
54456 | 26 | 510 | (294,66)
58764 | 26 | 822 | (317,119)
1742 | 27 | 743 | (9,77)
98925 | 27 | 24 | (534,135)
29363 | 29 | 392 | (158,133)
6564 | 30 | 570 | (35,89)
63464 | 32 | 527 | (343,9)
65040 | 33 | 105 | (351,105)
1598 | 37 | 599 | (8,118)
53945 | 39 | 998 | (291,110)
https://www.interdb.jp/pg/pgsql01.html
- TOAST
大字段数据,在字段数据大于2k的时候,会触发相应的机制,把数据按2k切分,存储到TOAST表中,原表使用专门的指针指向数据
brin
块级索引,空间占用小且有效
SMGR
/*
* This struct of function pointers defines the API between smgr.c and
* any individual storage manager module. Note that smgr subfunctions are
* generally expected to report problems via elog(ERROR). An exception is
* that smgr_unlink should use elog(WARNING), rather than erroring out,
* because we normally unlink relations during post-commit/abort cleanup,
* and so it's too late to raise an error. Also, various conditions that
* would normally be errors should be allowed during bootstrap and/or WAL
* recovery --- see comments in md.c for details.
*/
typedef struct f_smgr
{
void (*smgr_init) (void); /* may be NULL */
void (*smgr_shutdown) (void); /* may be NULL */
void (*smgr_open) (SMgrRelation reln);
void (*smgr_close) (SMgrRelation reln, ForkNumber forknum);
void (*smgr_create) (SMgrRelation reln, ForkNumber forknum,
bool isRedo);
bool (*smgr_exists) (SMgrRelation reln, ForkNumber forknum);
void (*smgr_unlink) (RelFileLocatorBackend rlocator, ForkNumber forknum,
bool isRedo);
void (*smgr_extend) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, char *buffer, bool skipFsync);
bool (*smgr_prefetch) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum);
void (*smgr_read) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, char *buffer);
void (*smgr_write) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, char *buffer, bool skipFsync);
void (*smgr_writeback) (SMgrRelation reln, ForkNumber forknum,
BlockNumber blocknum, BlockNumber nblocks);
BlockNumber (*smgr_nblocks) (SMgrRelation reln, ForkNumber forknum);
void (*smgr_truncate) (SMgrRelation reln, ForkNumber forknum,
BlockNumber nblocks);
void (*smgr_immedsync) (SMgrRelation reln, ForkNumber forknum);
} f_smgr;
static const f_smgr smgrsw[] = {
/* magnetic disk */
{
.smgr_init = mdinit,
.smgr_shutdown = NULL,
.smgr_open = mdopen,
.smgr_close = mdclose,
.smgr_create = mdcreate,
.smgr_exists = mdexists,
.smgr_unlink = mdunlink,
.smgr_extend = mdextend,
.smgr_prefetch = mdprefetch,
.smgr_read = mdread,
.smgr_write = mdwrite,
.smgr_writeback = mdwriteback,
.smgr_nblocks = mdnblocks,
.smgr_truncate = mdtruncate,
.smgr_immedsync = mdimmedsync,
}
};
操作不同介质的文件抽象层,在f_smgr中定义了操作的接口,当前默认实现为smgrsw中的对磁盘操作的函数,理论上支持其他存储介质,只需要实现对应的接口即可,当前只是作为一个简单的中转,具体的文件操作在smgr/md.c中
VFD
使用LRU缓存维护的fd,管理打开的文件描述符,主要代码在file/fd.c中,主要结构为
typedef struct vfd
{
int fd; /* current FD, or VFD_CLOSED if none */
unsigned short fdstate; /* bitflags for VFD's state */
ResourceOwner resowner; /* owner, for automatic cleanup */
File nextFree; /* link to next free VFD, if in freelist */
File lruMoreRecently; /* doubly linked recency-of-use list */
File lruLessRecently;
off_t fileSize; /* current size of file (0 if not temporary) */
char *fileName; /* name of file, or NULL for unused VFD */
/* NB: fileName is malloc'd, and must be free'd when closing the VFD */
int fileFlags; /* open(2) flags for (re)opening the file */
mode_t fileMode; /* mode to pass to open(2) */
} Vfd;
FSM
free space map,page中的数据在删除且vacuum之后,会有数据空洞,此时为了节约空间,在后续insert的时候,会尝试把数据insert到之前的page中,但是遍历page查找空间类似全表扫,所以为了加快这个过程,使用额外的数据结构记录空闲page的大小,insert的时候直接定位page
- 空闲空间不是精确统计,page默认大小为8k,把8k划分为255份,一份大小为32字节,此时使用一个字节就可以记录page中大约空闲的空间,
- 为了快速定位,fsm使用二叉树来维护,一个page大小为8192,除了header剩下的空间约为8000字节,使用叶子节点标记page大小,此时一个page大约可以记录4000个page,
- 一般使用三层fsm,此时前两层为辅助块,最后层page数目为4000^3,完全可以记录所有的数据块的使用情况,所以最初的时候fsm文件大小为 8192* 3,此时只使用到3个块记录大小,后期数据扩展的时候,此时fsm文件大小也会进行扩展
It is important to keep the map small so that it can be searched rapidly. Therefore, we don’t attempt to record the exact free space on a page. We allocate one map byte to each page, allowing us to record free space at a granularity of 1/256th of a page. Another way to say it is that the stored value is the free space divided by BLCKSZ/256 (rounding down). We assume that the free space must always be less than BLCKSZ, since all pages have some overhead; so the maximum map value is 255.
The binary tree is stored on each FSM page as an array. Because the page header takes some space on a page, the binary tree isn’t perfect. That is, a few right-most leaf nodes are missing, and there are some useless non-leaf nodes at the right. So the tree looks something like this:
0
1 2
3 4 5 6
7 8 9 A B
/*
* Structure of a FSM page. See src/backend/storage/freespace/README for
* details.
*/
typedef struct
{
/*
* fsm_search_avail() tries to spread the load of multiple backends by
* returning different pages to different backends in a round-robin
* fashion. fp_next_slot points to the next slot to be returned (assuming
* there's enough space on it for the request). It's defined as an int,
* because it's updated without an exclusive lock. uint16 would be more
* appropriate, but int is more likely to be atomically
* fetchable/storable.
*/
int fp_next_slot;
/*
* fp_nodes contains the binary tree, stored in array. The first
* NonLeafNodesPerPage elements are upper nodes, and the following
* LeafNodesPerPage elements are leaf nodes. Unused nodes are zero.
*/
uint8 fp_nodes[FLEXIBLE_ARRAY_MEMBER];
} FSMPageData;
fp_next_slot记录下一此使用的节点,目的是
- 在多进程写同一个表时候,避免对同一个page的竞争
- 记录下一个page,在顺序读写的时候可以有更高的性能
具体的查找算法为
/*----------
* Start the search from the target slot. At every step, move one
* node to the right, then climb up to the parent. Stop when we reach
* a node with enough free space (as we must, since the root has enough
* space).
*
* The idea is to gradually expand our "search triangle", that is, all
* nodes covered by the current node, and to be sure we search to the
* right from the start point. At the first step, only the target slot
* is examined. When we move up from a left child to its parent, we are
* adding the right-hand subtree of that parent to the search triangle.
* When we move right then up from a right child, we are dropping the
* current search triangle (which we know doesn't contain any suitable
* page) and instead looking at the next-larger-size triangle to its
* right. So we never look left from our original start point, and at
* each step the size of the search triangle doubles, ensuring it takes
* only log2(N) work to search N pages.
*
* The "move right" operation will wrap around if it hits the right edge
* of the tree, so the behavior is still good if we start near the right.
* Note also that the move-and-climb behavior ensures that we can't end
* up on one of the missing nodes at the right of the leaf level.
*
* For example, consider this tree:
*
* 7
* 7 6
* 5 7 6 5
* 4 5 5 7 2 6 5 2
* T
*
* Assume that the target node is the node indicated by the letter T,
* and we're searching for a node with value of 6 or higher. The search
* begins at T. At the first iteration, we move to the right, then to the
* parent, arriving at the rightmost 5. At the second iteration, we move
* to the right, wrapping around, then climb up, arriving at the 7 on the
* third level. 7 satisfies our search, so we descend down to the bottom,
* following the path of sevens. This is in fact the first suitable page
* to the right of (allowing for wraparound) our start point.
*----------
*/
结合代码理解
- 先判断root节点
- 从fp_next_slot或者midel node开始,向右上查找,直到找到复合的node
- 从这里开始向下查找
代码就是简单的对二叉树的操作,所有代码在freespace/fsmpage.c中,vacuum的时候会触发sfm的操作,具体的代码在freespce/freespace.c中。
VM
可见性映射表,记录数据变动的page,pg支持多版本,在数据变动的时候不会立即清除数据,而指挥打上tag,等待后续的vacuum进程进行数据的清理,vm记录数据的变动,让vacuum可以快速的清理数据,vacuum有两种模式,一种是lazy vacuum,一种是full vacuum,lazy 的时候不会跨page清理,此时可以使用vm文件,但是full vacuum的时候一般需要全表扫描,基本不会有太大的最用, vm是简单的bit位,0代表有数据变动,
内存
内存上下文,简单的理解就是一定范围内的内存池?
https://smartkeyerror.com/PostgreSQL-MemoryContext
insert
堆表insert操作
- 对应函数为heap_insert 1. heap_prepare_insert 设置 tuple header 2. RelationGetBufferForTuple 获取可用buffer 3. RelationPutHeapTuple 进行 insert 4. 设置 xlog 信息
insert 中可能会有 page 看见不足等问题,需要进行扩展,主要在 RelationGetBufferForTuple 函数中
RelationGetBufferForTuple:
1. insert 会优先使用上次 insert 操作的 page
如果空间足够,则
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
pageFreeSpace = PageGetHeapFreeSpace(page);
if (targetFreeSpace <= pageFreeSpace)
RelationSetTargetBlock(relation, targetBlock);
return buffer;
否则从 FSM 中寻找一个空间足够的页面
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
pageFreeSpace = PageGetHeapFreeSpace(page);
if (targetFreeSpace <= pageFreeSpace) // false
LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
targetBlock = RecordAndGetPageWithFreeSpace()
如果 FSM 中没有,则进行扩展,扩展时区分并发和非并发,没有并发的时候
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
pageFreeSpace = PageGetHeapFreeSpace(page);
if (targetFreeSpace <= pageFreeSpace) // false
LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
targetBlock = RecordAndGetPageWithFreeSpace()
if (!ConditionalLockRelationForExtension(relation, ExclusiveLock)) // 表加排他锁成功
buffer = ReadBufferBI(relation, P_NEW, RBM_ZERO_AND_LOCK, bistate);// 扩展
page = BufferGetPage(buffer);
PageInit(page, BufferGetPageSize(buffer), 0);
MarkBufferDirty(buffer);
RelationSetTargetBlock(relation, BufferGetBlockNumber(buffer));
如果有并发,则会在表加锁的时候尝试失败,然后进行bulk 扩展过程
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
pageFreeSpace = PageGetHeapFreeSpace(page);
if (targetFreeSpace <= pageFreeSpace) // false
LockBuffer(buffer, BUFFER_LOCK_UNLOCK);
targetBlock = RecordAndGetPageWithFreeSpace()
if (!ConditionalLockRelationForExtension(relation, ExclusiveLock)) // 表加排他锁 失败
LockRelationForExtension(relation, ExclusiveLock);
targetBlock = GetPageWithFreeSpace(relation, targetFreeSpace);
if (targetBlock != InvalidBlockNumber)
UnlockRelationForExtension(relation, ExclusiveLock);
return
RelationAddExtraBlocks(relation, bistate);
buffer = ReadBufferBI(relation, P_NEW, RBM_ZERO_AND_LOCK, bistate);// 扩展
page = BufferGetPage(buffer);
PageInit(page, BufferGetPageSize(buffer), 0);
MarkBufferDirty(buffer);
RelationSetTargetBlock(relation, BufferGetBlockNumber(buffer));
RelationAddExtraBlocks 批量扩展,大小为 min(512, lockWaiters * 20)
```