Mapreduce
利用普通机器组成的大规模计算集群进行并行的,高容错,高性能的数据处理函数框架
原始论文点这里,论文翻译点这里,有时间的话,自行对比翻译和原文
最终实现的目标是–实现一个分布式系统,对程序员隐藏底层分布式细节,程序员只需要定义map和reduce 函数即可。
map reduce实现为简单的kv输出,其中map接受源数据,生成kv的中间结果,中间结果保存在worker节点上。
reduce负责处理map产生的中间结果的kv数据,只是简单的数据处理过程.
他最先是受到lisp中map和reduce原语的启发,再加上当时Google现实的处理大量数据的需求,从他们现有的系统抽象而来的。
在论文中,使用了一个单词统计的案例,此时实现map函数用来分割文本,切分出最基本的单词。然后再使用reduce进行聚合操作,
// 输出单词以及出现的次数,map端输出1
map(String key,String value):
// key: 文档名
// value: 文档内容
for each word w in value:
EmitIntermediate(w,"1");
// 针对相同的key,次数+1
reduce(String key, Iterator values):
// key: 一个单词
// value: 计数值列表
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
- 执行过程
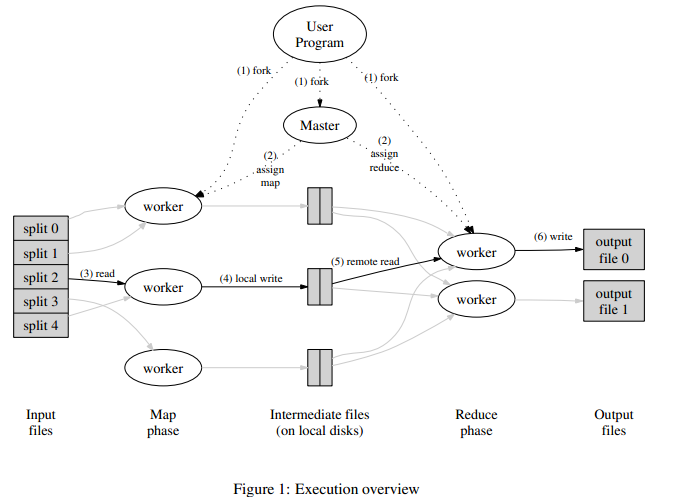
- 文件划分
- 主节点划分任务
- 按照划分的任务启动worker,执行map任务
- worker节点的数据生成为中间结果,保存在本节点
- 所有map任务执行完成之后,reduce得到对应中间节点的文件路径,通过rpc读取文件,进行reduce任务
- reduce任务完成之后,最终结果写入目标文件
一个mr任务完成之后,回得到n(reduce)个结果文件,可以按照需求处理文件,可以直接使用,或者继续作为其他mr的输入,mr任务是可以嵌套的。
主节点
- 记录map和reduce任务的状态,例如是否开始,是否结束,执行时间等
- 协调工作节点,确定工作状态。确定任务是否需要重试,是否需要back up等
容错性
- 工作节点失败
主机点定时检测工作节点状态,如果无法链接,此时需要把此丢失的工作节点上的所有的任务重新安排到其他节点上执行。包括已完成的map任务,因为mr任务是需要等所有map任务结束之后才能执行reduce任务,其map任务的数据在保存在worker节点上的。所以需要重新执行map任务。至于reduce任务,由于他的输出之最终的数据结果,且需要记录到文件。所以为了避免重复的数据产生,已完成的reduce任务不重试,前提是输出数据已经保存到其他节点上。 - 主节点错误 一般是直接重试整个mr任务,因为mr的主节点应该是需要选择集群中比较可靠的节点,此时有理由怀疑其他节点也可能出现问题,所以此时选择整个重新执行,当然也可以恢复主节点,从记录的回复点重新执行
- 工作节点失败
backup task mr中由于任务切分不一定均衡或者不同节点计算能力不同,有的任务执行格外慢,此时可以在其他空闲节点上执行相同的任务,此时集群中可能有多个相同的任务,最终哪一个任务先完成,主节点就会终止其他未完成的工作节点。
上面就是原始的mr描述,理所当然的可以想到一些提升的地方
- 平均的划分任务文件,尽量任务均衡
- 流式计算,在中间结果产生的时候,直接保存中间文件到reduce节点,避免最后集中处理中间结果时候的网络带宽消耗
- 本地计算mr,有的mr任务没必要在不同节点上执行,直接划分到一个节点或把的某些任务划分到一个节点上,实现本地计算。避免网络IO
- 提前进行reduce操作,可以使用reduce任务提前处理中间结果,减少中间结果的大小
- 记录计算节点的状态,多次执行任务的时候,可以记录某节点的处理速度,在下一个mr任务划分的时候,按照此信息划分任务
- map和reduce之间是完全串行的,如果有多个MR任务嵌套的话,由于每个mr必须实现map和reduce,会导致链路过长,实现和调试困难
- 性能无法达到要求
6.824 LAB
- 先掌握go,重点为go的协程,管道,以及channel
- 代码框架已经给出来了,需要自己实现分布式的worker和master
- 可以先实现简单的无状态的mr,可以通过
test-mr.sh中的前面的测试
worker
map和reduce的执行节点,需要从master获得任务,按照任务的类型,执行不同的job
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
for {
job := getJob()
if job.JobTypeY == UNFINISH {
time.Sleep(time.Second)
} else if job.JobTypeY == DOMAP {
doMapJob(job.FileName, job.NReduce, job.JobId, mapf)
reportDone(job.JobId)
} else if job.JobTypeY == DOREDUCE {
doReduce(job.JobId, job.NMap, reducef)
reportDone(job.JobId)
} else {
return
}
}
}
map打开文件,执行map操作,然后把数据按照hash切分到不同的文件中
func doMapJob(filename string, nReduce int, jobid int, mapf func(string, string) []KeyValue) {
intermediate := []KeyValue{}
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", filename)
}
file.Close()
kva := mapf(filename, string(content))
intermediate = append(intermediate, kva...)
kvs := make([][]KeyValue, nReduce)
for _, v := range intermediate {
idx := ihash(v.Key) % nReduce
kvs[idx] = append(kvs[idx], v)
}
for idx, kv := range kvs {
ofilename := fmt.Sprintf("mr-tmp-%v-%v", jobid, idx)
ofile, _ := os.Create(ofilename)
enc := json.NewEncoder(ofile)
for _, v := range kv {
enc.Encode(&v)
}
if err := ofile.Close(); err != nil {
log.Fatalf("close file error %v", ofilename)
}
}
}
reduce操作类似,但是在论文中,reduce需要注意的是先输出数据到临时文件中,完成之后再重命名文件,目的是避免reduce失败之后,重新执行reduce操作产生部分重复的错误的文件,map没有这个操作的原因是map失败之后,重新执行可以覆盖原中间文件,或者执行backup操作,得到的最终只有一个中间文件
func readFromFile(files []string) []KeyValue {
var kva []KeyValue
for _, filepath := range files {
file, _ := os.Open(filepath)
dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
kva = append(kva, kv)
}
file.Close()
}
return kva
}
func doReduce(jobid int, nMap int, reducef func(key string, values []string) string) {
ifilenames := make([]string, nMap)
for mapTask := 0; mapTask < nMap; mapTask++ {
ifilenames[mapTask] = fmt.Sprintf("mr-tmp-%v-%v", mapTask, jobid)
}
intermediate := readFromFile(ifilenames)
sort.Sort(ByKey(intermediate))
ofilename := fmt.Sprintf("mr-tmp-%v", jobid)
ofile, _ := os.Create(ofilename)
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
ofile.Close()
oname := fmt.Sprintf("mr-out-%d", jobid)
os.Rename(ofile.Name(), oname)
}
6.824的实验是使用单机模拟分布式,真正的分布式上reduce需要从worker节点拉取中间文件。这里只是简单的模拟
master
master负责维护worker节点以及worker上面job的调度情况,核心的操作为
// 初始化map job,启动服务
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{}
c.makeMapJobs(files, nReduce)
c.server()
return &c
}
// worker 通过rpc调用此函数获得job,此时此函数中记录job的调度情况
func (c *Coordinator) DistributeJob(args *ExampleReply, reply *Job) error {
mu.Lock()
defer mu.Unlock()
if c.Status == DOMAP {
if len(c.JobChannelMap) > 0 {
*reply = *<-c.JobChannelMap
c.JobMap[reply.JobId].jobstatus = DOING
} else {
if c.allJobDone() {
reply.JobTypeY = UNFINISH
c.Status = DOREDUCE
c.makeReduceJobs()
} else {
reply.JobTypeY = UNFINISH
}
}
} else if c.Status == DOREDUCE {
if len(c.JobChannelRed) > 0 {
*reply = *<-c.JobChannelRed
c.JobMap[reply.JobId].jobstatus = DOING
} else {
if c.allJobDone() {
c.Status = DONE
reply.JobTypeY = UNFINISH
} else {
reply.JobTypeY = UNFINISH
}
}
} else {
reply.JobTypeY = DONE
}
return nil
}