LevelDB源码阅读
LevelDB: version 1.23
Date: Thu Oct 20 15:32:47 2022
CPU: 16 * AMD Ryzen 9 5900HS with Radeon Graphics
CPUCache: 512 KB
Keys: 16 bytes each
Values: 100 bytes each (50 bytes after compression)
Entries: 1000000
RawSize: 110.6 MB (estimated)
FileSize: 62.9 MB (estimated)
------------------------------------------------
fillseq : 1.394 micros/op; 79.3 MB/s
fillsync : 1208.178 micros/op; 0.1 MB/s (1000 ops)
fillrandom : 1.948 micros/op; 56.8 MB/s
overwrite : 2.448 micros/op; 45.2 MB/s
readrandom : 3.251 micros/op; (864322 of 1000000 found)
readrandom : 2.947 micros/op; (864083 of 1000000 found)
readseq : 0.126 micros/op; 878.1 MB/s
readreverse : 0.216 micros/op; 511.4 MB/s
compact : 473557.000 micros/op;
readrandom : 2.174 micros/op; (864105 of 1000000 found)
readseq : 0.111 micros/op; 997.1 MB/s
readreverse : 0.185 micros/op; 598.0 MB/s
fill100K : 530.603 micros/op; 179.8 MB/s (1000 ops)
crc32c : 0.904 micros/op; 4322.1 MB/s (4K per op)
snappycomp : 2.353 micros/op; 1659.9 MB/s (output: 55.1%)
snappyuncomp : 0.390 micros/op; 10026.4 MB/s
read: d019e3605f222ebc5a3a2484a2cb29db537551dd
小且完整的工业存储实现,其中有许多细节是可以借鉴的。这里没有完整的深入每一行代码,后续会时不时的慢慢补充
- 2022-05-17 初步阅读代码,了解组件及大致执行逻辑
- 2022-10-20 重读部分代码,感觉自己貌似有了些许长进
编译
git clone --recurse-submodules https://github.com/google/leveldb.git
cd leveldb
VSCode安装cmake插件之后,打开项目,cmake插件自动配置,此时使用shift+p设置cmake: set build target之后,再使用shift+p选择cmake: build即可编译目标模块,d019e3605f222ebc5a3a2484a2cb29db537551dd中测试文件进行了调整,全部合并到leveldb_tests中,调试时按照想要了解的模块,自己注释其他测试文件,重新编译即可。此时可以在文件中断点调试,或者使用gdb调试
slice
字符串的浅拷贝实现,使用一个指针和指针长度实现,类似c++后来实现的string_view,如果使用string,则在传递数据的时候会进行拷贝操作,有性能损失。另一个目的是为了自主可控,确保数据在传输的过程中不会造成太多的数据副本。所以拷贝构造函数使用的是默认的系统函数,使用浅拷贝
Slice(const Slice&) = default;
Slice& operator=(const Slice&) = default;
status
自定义信息模块,把状态码和状态信息进行压缩,压缩格式如下
Status::Status(Code code, const Slice& msg, const Slice& msg2) {
assert(code != kOk);
const uint32_t len1 = static_cast<uint32_t>(msg.size());
const uint32_t len2 = static_cast<uint32_t>(msg2.size());
const uint32_t size = len1 + (len2 ? (2 + len2) : 0);
char* result = new char[size + 5];
std::memcpy(result, &size, sizeof(size));
result[4] = static_cast<char>(code);
std::memcpy(result + 5, msg.data(), len1);
if (len2) {
result[5 + len1] = ':';
result[6 + len1] = ' ';
std::memcpy(result + 7 + len1, msg2.data(), len2);
}
state_ = result;
}
TIPS: 对于数字,之际拷贝地址可以直接序列化,不需要使用 to_string,取数的时候直接取字节码,然后static_cast就可以了
数值编码
leveldb中几乎所有的数据都会和数据格式的编码或多或少的有联系,首先数据的存储不能直接简单的to_string然后存储字符串,其次对于整形的变长编码,他会把数据的二进制编码按7拆分,在每个字节的第一位使用1表示是否为数据的结尾,例如int(1)编码为00000001,11 10101010会编码为10101010 00000111,对应压缩和解压代码如下,变长编码是一种编程技巧,int类型是4字节,long是8字节。当存储的数据小的时候。可以节约空间。并且我们有理由相信,程序中大部分场景使用的是小数字。
char* EncodeVarint32(char* dst, uint32_t v) {
// Operate on characters as unsigneds
uint8_t* ptr = reinterpret_cast<uint8_t*>(dst);
static const int B = 128;
if (v < (1 << 7)) {
*(ptr++) = v;
} else if (v < (1 << 14)) {
*(ptr++) = v | B;
*(ptr++) = v >> 7;
} else if (v < (1 << 21)) {
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = v >> 14;
} else if (v < (1 << 28)) {
const char* GetVarint32PtrFallback(const char* p, const char* limit,
uint32_t* value) {
uint32_t result = 0;
for (uint32_t shift = 0; shift <= 28 && p < limit; shift += 7) {
uint32_t byte = *(reinterpret_cast<const uint8_t*>(p));
p++;
if (byte & 128) {
// More bytes are present
result |= ((byte & 127) << shift);
} else {
result |= (byte << shift);
*value = result;
return reinterpret_cast<const char*>(p);
}
}
return nullptr;
}
除了变长之外,还有定长编码,以及对应的32位,64位的实现等,在实际的数据处理中,会有记录数据长度等操作,就会使用编码操作,把数值编码到数据中。定长编码是直接存储字节序。
Arena
自定义内存池,设计思路是申请内存和分配内存隔离,申请内存的时候多申请,分配内存的时候从已申请的内存中分配,使用vector维护内存空间,LevelDB中在memtable中使用,理论上可以用在任何想使用的组件中,但是实际上数据变动最多的地方是memtable,所以暂时只发现只有这里使用。
- 对于大空间(大于kBlockSize / 4的空间,大于kBlockSize = 4096),则直接申请,独占一个block,不受block大小的限制,且不改变之前记录的block的指针状态
- 对于小空间
- 第一次会申请大小为4k的空间,然后记录当前空间的指针及空间使用情况,然后从空间上分配内存,且空间push到vector中
- 之后的空间申请如果在当前block上可以继续分配,则在block上直接分配
- 如果不满足条件,则重新分配,之前残留的空间直接丢弃,且不计入使用空间统计
- 对于空间的统计情况,使用原子变量
std::atomic<size_t> memory_usage_;记录,因为Arena在skiplist中使用的时候,可能有并发的情况
TIPS: 原子类型的细节需要调研
char * pool = area->Allocate(size); // 不对齐的申请
// char * pool = area->AllocateAligned(size); // 申请对齐的空间
auto mem = new (pool) char(size);
Allocate(size) {
if (size < alloc_bytes_remaining_) {
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
return AllocateFallback(size);
}
SkipList
来自论文Skip lists: a probabilistic alternative to balanced trees,其中介绍了跳表的实现和其他不同结构之间的对比情况,
需要重修概率论
跳表使用使用概率均衡的技术,大部分操作都可以实现O(log n)的时间复杂度,可以参考上面的文章,这里总结几个点
- 跳表可以简单的理解为链表的+index的实现,index的目的是为了快速的查找数据
- 跳表在增加节点的时候,使用概率为0.25来确定使得否增加下一层,在这个概率下,空间需要花费的代价为
(cost(node) * 1.33)
static const unsigned int kBranching = 4;
int height = 1;
while (height < kMaxHeight && rnd_.OneIn(kBranching)) {
height++;
}
- 查找的时间复杂度可以抽象的理解为二分查找的
O(log n) - 跳表的操作的时间复杂度和红黑树几乎差不多,但是有一点功能是红黑树无法实现的,即
range search,红黑树由于结构特性,无法进行类似的操作,跳表可以定位node之后,可以根据node间的链接实现顺序遍历 - insert的时候先查找位置,然后按概率计算层高,再进行插入
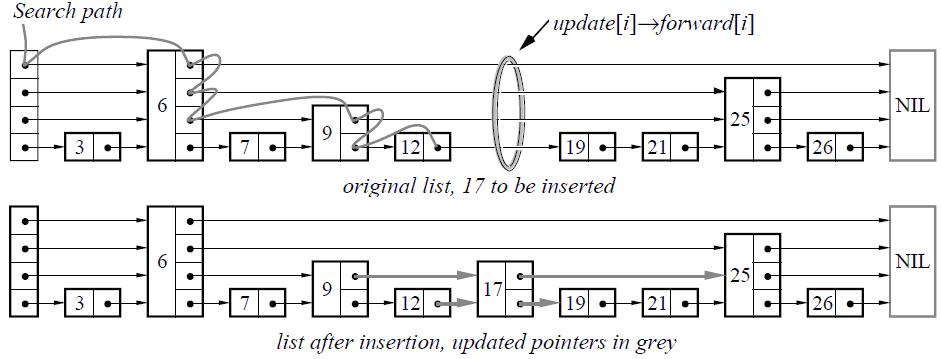
- 容易实现并发操作,并发的时候只需要对极少的节点加锁即可,但是红黑树由于需要变形旋转需要对整棵树加锁,所以这也是大部分存储使用skiplist的作为memtable的理由之一
1. c++并发编程
2. 三种并发- max_heights_ 使用memory_order_relaxed,skiplist只允许一写多读,max_height_只有写才会改变
- insert设置新节点的next,使用NoBarrier_Next和NoBarrier_SetNext操作,此时对node使用memory_order_relaxed操作,此时其他线程无法看见新节点
- insert设置新节点的forward,此时使用SetNext的memory_order_release,此时所有线程可以看见新节点
但是由于skiplist 分层,所以此时只能看见当前插入的这一层,而查询是需要从顶层往下查的,所以insert需要从底层开始,否则可能出现上层查询节点存在,但是下层不存在
- leveldb中,skiplist没有delete操作,如果需要实现,则需要实现类似insert中的部分操作,查找到pre,在设置节点即可。
template <typename Key, class Comparator>
void SkipList<Key, Comparator>::Insert(const Key& key) {
Node* prev[kMaxHeight];
// 设置pre,从顶层开始查找,记录的是每一层的当前节点的pre节点
Node* x = FindGreaterOrEqual(key, prev);
assert(x == nullptr || !Equal(key, x->key));
// 随即高度
int height = RandomHeight();
if (height > GetMaxHeight()) {
// 如果高度比之前的高,则把prev之前高度节点到height之间的node设置为head_
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
max_height_.store(height, std::memory_order_relaxed);
}
x = NewNode(key, height);
// 使用height设置当前节点和pre以及next阶段之间的链接
for (int i = 0; i < height; i++) {
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
}
std::atomic<Node*> next_[1];,不能是next_[0],因为0的时候sizeof不计算这位,大小不对,不能是二级指针,因为此时next在后续的使用中,上层next_是nullptr,无法直接操作,只有使用数组提前占位,才可以设置node,自己手写的时候需要注意。也可以再insert的时候注意于head的相对关系。
MemTable
SkipList的封装,长期处于内存中,活动的table只有一个,满的之后冻结落盘。基础操作为add和get,使用MemTableIterator访问memtable。
MemTableIterator是SkipList的迭代器的封装。持有一个跳表和node,使用SeekToFirst和SeekToLast定位node之后,开始使用
- add编码数据和类型以及长度和key等,拼接为一个buffer,然后insert到skiplist中
// Format of an entry is concatenation of:
// key_size : varint32 of internal_key.size()
// key bytes : char[internal_key.size()]
// tag : uint64((sequence << 8) | type)
// value_size : varint32 of value.size()
// value bytes : char[value.size()]
- 使用迭代器seek到node,然后获得数据,解码,判断数据类型
DBImpl
DB的具体实现,对外接口使用DB对象,但是内部实际调用的还是DBImpl实例
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) {
return DB::Put(o, key, val);
}
Status DBImpl::Delete(const WriteOptions& options, const Slice& key) {
return DB::Delete(options, key);
}
- 新建
- 恢复
- 写
1. 使用WriteBatch打包一批写入数据 2. 限制一写多读,WriteBatch会添加到队列,等待写入消耗 3. 写入会有多种中间状况- 当前正在L0的compact,此时如果不是强制异步写,则需要等待1s让出资源,等待compact完成,但是最多只能等待一次
- mem空间不足,需要进行 compact, 等待
- L0 SST超过限制,等待compact
这里几条应该是写入的最大的性能瓶颈,RocksDB中应该有解决的方案,后续可以看看他的写入流程
- 读
1. 三层读取。存在读放大的问题
2. 先都memtable 3. 再都inmem 4. 读取L0层 5. 读取其他层 6. 读取文件上的数据的时候使用Version::Get,内部先从L0开始,然后在依次向下读取,能进行key的比对的依据是version中保存文件的FileMetaData - compact
- lock机制
WriteBatch
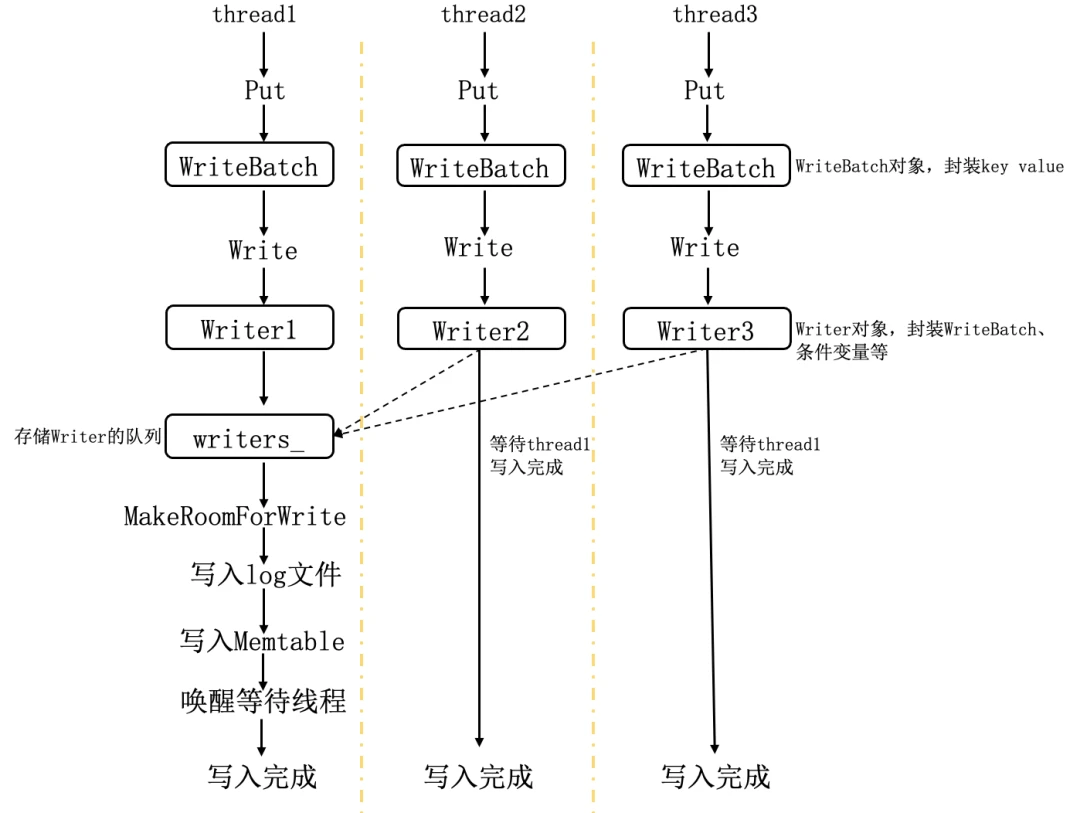
写操作的主要操作对象,主要步骤是把操作的数据打包为一个buffer,然后使用WriteBatch::Iterate操作handler实现insert操作,hanle是一个实现put和delete的接口,所以这里是把数据和操作分离了,这里有几点细节
- WriteBatch的数据格式为
seq|countkey|{type|key|val},batch添加一个数据的时候,除了正常添加数据,还会count++,用于在WriteBatch::Iterate的时候检测当前批次数据数量是否正确 - 一个batch的数据只有一个sequence,batch写完之后,数值加一,
- 有標記控制是否使用使用同步寫。默認為同步寫,異步寫入的速度快,但是可能導致系統崩潰的時候丟數據,所以爲了分攤大量數據的同步寫的cost,這裏設計WriteBatch來打包數據,進行一次同步寫操作,因爲是順序寫入磁盤,所以寫入速度可以接受
- 写入操作具有原子性,在写数据的时候会先写日志然后再写数据,当写日志之前或者写日志过程中宕机,下次重启时恢复数据库的时候直接丢弃异常日志。或者写完日志之后宕机,系统在下次启动之后都是确保数据的原子性,
PosixEnv
posix环境资源的实现,继承自env,目的是便于实现不同平台下的代码,
- 线程池,一个简单的例子 https://github.com/progschj/ThreadPool
- 日志
- 文件
WAL日志
https://leveldb-handbook.readthedocs.io/zh/latest/journal.html
日志在写数据之前记录,写完之后立刻flush,之后才是真正的写数据到memtable,日志文件会一直保存,直到数据落盘才删除,即memtable变为immemtable且compact(数据落盘)之后才删除,如果期间系统异常,则日志文件保存,到下次重启之后回复之后才删除,
(log::Writer)
写数据之前需要预写日志,目的是为了保证数据安全,在操作数据异常的时候可以使用日志恢复数据,按block划分,一个block大小为32k,一个block有四种状态
- kFullType
一个block可以存完数据 - kFirstType
一个block存不下数据,标记为第一个block - kLastType
最后一个block - kMiddleType
中间的block
每一个block中的数据的组织格式为crc|len(2)|type(1)|values,其中values的数据来自于前面的WriteBatch打包的数据,是一个整体,没有做太多的处理,主要的调用方法为
- DBImpl::Write
- DBImpl::NewDB
- VersionSet::LogAndApply
- VersionSet::WriteSnapshot
(log::Reader)
wal对应的读取操作
LRUCache
https://leveldb-handbook.readthedocs.io/zh/latest/cache.html
缓存模块,测试文件为cache_test.cc。
ShardedLRUCache
LRUHandle的包装,主要原因是LRUHandle的接口都加锁,所以这里使用ShardedLRUCache包装一下,使用16个LRUHandle来管理缓存,以提高并发时候的操作效率。uint32_t Shard(uint32_t hash) { return hash >> (32 - kNumShardBits); }会使用前4个bit计算位置,得到对应的LRUHandle对象,之后的操作使用此对象处理,相当于LRUHandle的hash表。LRUCache
LRU的实现,使用HandleTable作为hash表保存的数据。LRUHandle为链表保存数据,主要细节为
- 使用hash表保存数据
- 使用一个LRUHandle维护使用情况,数据在缓存中的时候,要么只是在缓存中,保存在lru_链表中,或者是使用中的数据,保存在
in_use_中 - 使用引用标记数据的使用,只有当引用为0的时候,才会删除数据,当数据存在在缓存中的时候,引用默认为1,为0则表示不缓存且没有外部引用
- 对于重复的key,会直接替换
- 容量不足的时候。替换lru_中的数据,
in_use_中的数据不操作 - 链表在append的时候,总是添加在链表头节点
LRUHandle
双向链表,在hash表中会保存数据,在LRU中会维护使用情况,- remove,直接设置链接,跳过当前节点
void LRUCache::LRU_Remove(LRUHandle* e) { e->next->prev = e->prev; e->prev->next = e->next; }- LRU_Append,insert操作,把节点append在链表之前
void LRUCache::LRU_Append(LRUHandle* list, LRUHandle* e) { // Make "e" newest entry by inserting just before *list e->next = list; e->prev = list->prev; e->prev->next = e; e->next->prev = e; }HandleTable LRUHandle的二维数组,使用连地址法来处理冲突,基础容量为4,rehash按2扩充空间
缓存有两种,一种是用来缓存的打开的SST table的cache,一种是用来缓存使用的block的cache
SST
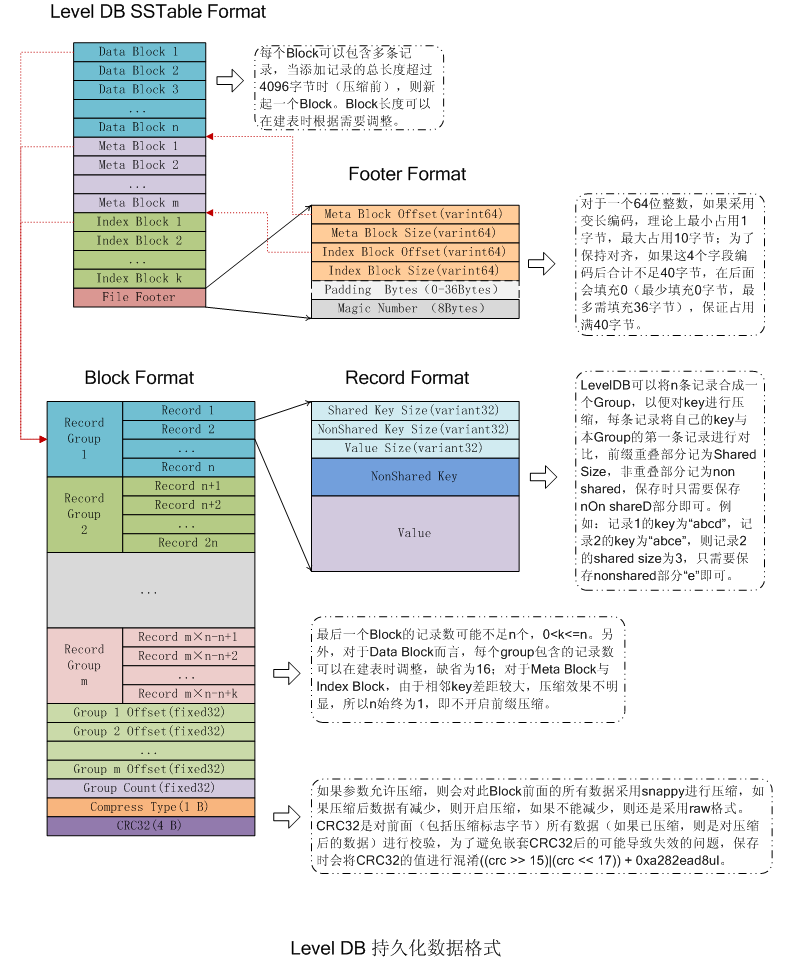 具體格式如圖,文件最后是footer,保存mata和index的大小和偏移,
具體格式如圖,文件最后是footer,保存mata和index的大小和偏移,
footer (
Footer::EncodeTo)int64 * 2 | mata int64 * 2 | index padding magicnumBlockBuilder
磁盘读写按照一定大小读取比较有效率,leveldb按照4K大小组织文件,4K为一个block,block按照一个一个的条目编码数据,格式为slen|uslen|vlen|uskey|v,s指的是share,如下的例子
{
string key1 = "abcd", v1 = "vv1vv";
string key2 = "abce", v2 = "vv2vv";
string key3 = "abxf", v3 = "vv3vv";
encode = {0 4 5 abcd vv1vv | 3 1 5 e vv2vv | 2 2 5 xf vv3vv}
}
第一个记录不编码,第二个和第一个对比,编码存取,key抽取相同的前缀,记录长度,之后的数据都按前一个数据编码,如果数据太多,可能后面的key和之前的key差距比较大,查找的时候只能全部解码然后寻找key,所以设计可以控制每隔固定数量的key存一个完整的key,称为重启点,按重启点划分为不同的group,此时且记录key的偏移,此时查找的时候可以按照偏移取key然后使用二分查找等方式快速查寻。在持久化的时候,block末尾记录group的大小,再使用一个bit记录压缩格式,再使用4个bit记录crc。这就是block的基本格式 除了footer使用单独的编码格式之外。其余的mata,index,data都使用block的格式编码数据, block 是一个读写单位,所以如果使用场景大量批量读写,则可以适当增加block size,如果单点读写比较多,则可以减少block size, 这要平衡
- 写入流程
TableBuilder::Add
if (r->pending_index_entry) // 新的block设置index
index_block.Add
filter_block->AddKey // 设置filter
data_block.Add // 添加数据到data_block,如果大小达到限制,flush
if (estimated_block_size >= r->options.block_size)
TableBuilder::Flush()
TableBuilder::WriteBlock // 写block
BlockBuilder::Finish // 打包数据,编码group offset
compression // 压缩
TableBuilder::WriteRawBlock // 写压缩之后的数据,设置编码格式和crc
r->pending_index_entry = true; // 设置标记为true,记录index
读取流程
讀取的時候逆向操作,校監crcindex index的一個條目對應的是一個datablock中的最大的key以及block的偏移和大小,key使用FindShortestSeparator計算得出,確保他計算的key是當前保存的datablock中的最大值加1,目的是便於查找
start: abcdef limit: abcdgh FindShortestSeparator--> start = abcdf // 公共前綴加1
- immemtable的寫入
https://hardcore.feishu.cn/docs/doccn4w8clvork96K3dqQnJRh9g# https://my.oschina.net/fileoptions/blog/903206
WriteLevel0Table
{
mutex_.Unlock(); // 不加鎖是因爲immemtable不可變,所以沒有并發問題
s = BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);
BuildTable :{
// get file
// add values
builder->Add(key, iter->value());
s = builder->Finish();
Finish: {
// filter
// metaindex
// index
// footer
}
file->sync();
file->close();
}
mutex_.Lock();
}
具體的細節可以參考代碼的文檔,
迭代器
訪問特定數據結構的抽象,使數據的訪問和存儲分離,可以參考STL的實現,levelDB中對不同的組件實現不同的迭代器
- MemTableIterator
- LevelFileNumIterator
- Block::Iter
version
https://leveldb-handbook.readthedocs.io/zh/latest/version.html
本质上是使用版本号组成key,用来查询数据,之前数据存放的时候,是有记录seq的,version是专为这种行为设计的系统,
需要管理磁盘文件的版本,不同的版本使用不同的Sequence,key中含有LastSequence信息,所以本质上还是key的查询
- get
需要读取磁盘中的文件,version中保存FileMetaData,所以可以快速的定位数据的sst,然后直接读取sst,对于L0,由于存在重复key,所以 需要进行key的比较,读取多个文件
compact
定期的数据的整理合并操作
- minor compaction
immemtable持久化为SST,可以手动使用TEST_CompactMemTable触发,主要方式是设置DBImpl::Write的WriteBatch参数为null,此时在MakeRoomForWrite中,会根据参数导致选择compact的分支,会进行CompactMemTable操作,此时之前的数据会固化到文件中。也可以自动触发,当memtable 满了之后,会进行相同的操作。- TIPS: 此时version中会保存SST的相关信息,包括beginkey和endkey,以及版本信息
- 文件不一定是level0,对于大文件,预测level0可能很快到达限制,可以在一定条件下直接把文件放在较高层。
- Major Compaction
sst之间向下合并,其会把相同key的不同版本的数据合并,可以手动使用TEST_CompactRange触发,此时可以选择需要compact的level和start key和endkey,他会把文件向下层合并,这里需要注意的是- level0会有重叠的key,compact的时候需要选择beginkey endkey以及他中间覆盖的文件进行compact操作,否则会残留下old key,
- sst不一定是向下推一层,可以选择想要合并的层数,对于level 0,使用文件个数计算score,对于其他层,使用文件大小计算
for (int level = 0; level < config::kNumLevels - 1; level++) { double score; if (level == 0) { // We treat level-0 specially by bounding the number of files // instead of number of bytes for two reasons: // // (1) With larger write-buffer sizes, it is nice not to do too // many level-0 compactions. // // (2) The files in level-0 are merged on every read and // therefore we wish to avoid too many files when the individual // file size is small (perhaps because of a small write-buffer // setting, or very high compression ratios, or lots of // overwrites/deletions). score = v->files_[level].size() / static_cast<double>(config::kL0_CompactionTrigger); } else { // Compute the ratio of current size to size limit. const uint64_t level_bytes = TotalFileSize(v->files_[level]); score = static_cast<double>(level_bytes) / MaxBytesForLevel(options_, level); } if (score > best_score) { best_level = level; best_score = score; } }- sst记录一个查询次数,当一个文件被查询多次且是无效查询的时候的,当达到一定次数就会触发compcat操作,理由是他可能和其他文件有太多的重复的key,需要被清理以平衡io操作,这里的依据是的一次额外的compact操作的cost和多次的无效seek的均衡。
compact { BackgroundCompaction { if (imm_ != nullptr) { CompactMemTable(); return; } Compaction* c; if (is_manual) { // 执行manual compact,优先级最高,获得Compaction c = versions_->CompactRange(m->level, m->begin, m->end); } if (c == nullptr) { // 不做处理,不需要compact }else if (!is_manual && c->IsTrivialMove()) { // 仅仅只需要移动文件,例如最开始的时候下层没有需要合并的文件,直接移动文件,修改元数据即可 } else { // 执行compact CompactionState* compact = new CompactionState(c); status = DoCompactionWork(compact); } } // 多个文件的合并操作,会处理过期或者需要删除的数据 DoCompactionWork { Iterator* input = versions_->MakeInputIterator(compact->compaction); while (input->Valid() && !shutting_down_.load(std::memory_order_acquire)) { if (has_imm_.load(std::memory_order_relaxed)) { // 如果有minor compact,则优先处理 } // 判断重叠,重叠太多影响查询,直接终止 if compact->compaction->ShouldStopBefore(key) break; // 处理key { // 如果是delete // 或者是sequence小于当前使用中的sequence // 或者更高层没有这个key drop = true; } if (!drop) compact->builder->Add(key, input->value()); } } }
由于compact的时候,会占用一定的系统资源,所以如果发生compaction的时候
- 如果是minor compact,则减缓写操作,释放一定的系统资源
- 如果是Major Compaction,则暂停操作。等待compact任务完成