GFS
GFS是一个大规模可扩展的可容错的分布式文件系统。Google三大篇论文之一
- GFS的特点
- 运行在廉价的机器上,节约成本
- 灵活性强,可随意扩展,容错性强
- 文件尾部追加数据,不会有太多的数据变动
架构
一个单独的master节点和多个datachunk节点,maste管理元数据信息,包括chunkhandle信息,文件和chunk的映射信息,以及chunkserver的变动信息等。master使用心跳定时和chunkserver同步关键信息。使用单个master的目的是为了简化设计,同时为了避免单点故障,master节点每次操作都和backup master同步数据,master存储的3种关键元数据为
- 文件和Chunk的命名空间
- 文件和Chunk的对应关系
- 每个Chunk副本的存放地点
存放在master上,在chunkserver变动的时候难以维护,每个server自己维护自己的信息,然后让master自行同步的方式会简单许多。 这些信息保存在内存中,且1和2的数据变动会保存在日志文件中,每次mater故障恢复的时候,只需要使用此日志就可以恢复到原来的状态,至于3,则保存在chunkserver中,master会使用心跳定时从chunkserver更新此信息到内存中,master的内存承载能力一般是可以维护这些数据,一条master中的信息可以维护一个chunk,一般一条信息可以在64内保存下来,且由于数据的在小范围变化不大,使用一定的压缩方法可以大大的节约空间。
日志记录上面1和2的数据变动信息,用于故障恢复,为了避免日志信息过于庞大,加入检查点机制,恢复时只要回放检查点之后的日志即可。
chunkserver保存chunk数据,同时维护server上的chunk信息,GFS把大文件切分为64M的chunk文件,64M的原因是
- Google实际存储的数据较大其大部分时候使用顺序读写文件,所以大文件的读写时间可以在接受范围内
- 大文加可以减少master中的元数据信息,读写的时候,可以对一个大文件进行多次读写,避免了小文件需要多次向master查询位置信息
- 大文件可以避免小文件反复从server读取,使server变成热点
chunk一般是3个数据副本
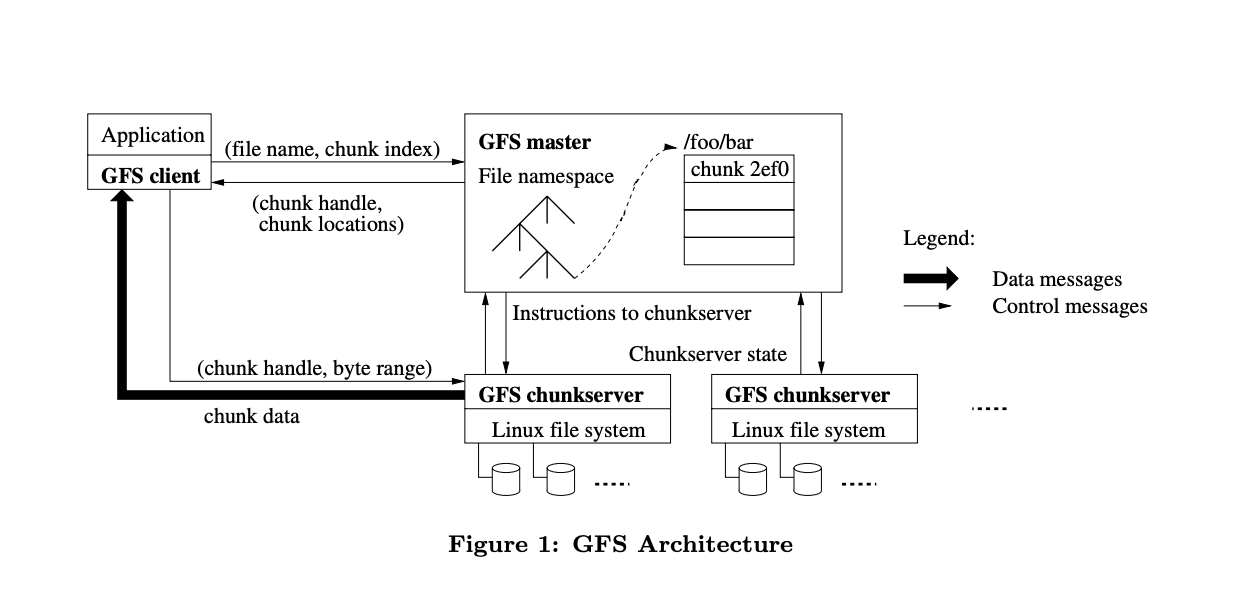
读取操作
- C sends filename and offset to coordinator (CO) (if not cached)
- CO finds chunk handle for that offset
- CO replies with list of chunkhandles + chunkservers only those with latest version
- C caches handle + chunkserver list
- C sends request to nearest chunkserver chunk handle, offset
- chunk server reads from chunk file on disk, returns to client
一致性问题
弱一致性。易实现, 随机写会有offset重复的问题,但是master限定操作顺序,理论上最终的数据是一致的,但是在client看来,数据是不确定的,因为副本不是要求立刻同步的, append only限定append的offset,所以每个offset上数据是一致的
Read other posts